Maîtriser la facturation GitHub Copilot
Auteur : William OGEZ
GitHub Copilot change de modèle de facturation. Après lespremium requests, la nouvelle facturation enAI Creditschange complètement la donne. De 0,04 $ à plusieurs dizaines de dollars en quelques minutes, comment comprendre cette nouvelle grille tarifaire ?
GitHub Copilot est un agent IA proposé par GitHub, en partenariat avec Microsoft. Concurrent direct de Claude Code et de Codex, son principal atout est de donner accès à plusieurs modèles (Claude, GPT, Gemini...) directement dans une même offre.
Sa facilité de déploiement à grande échelle en a fait un choix de premier plan pour de nombreuses entreprises. Mais ce positionnement est aujourd’hui remis en question par le récent changement de facturation.
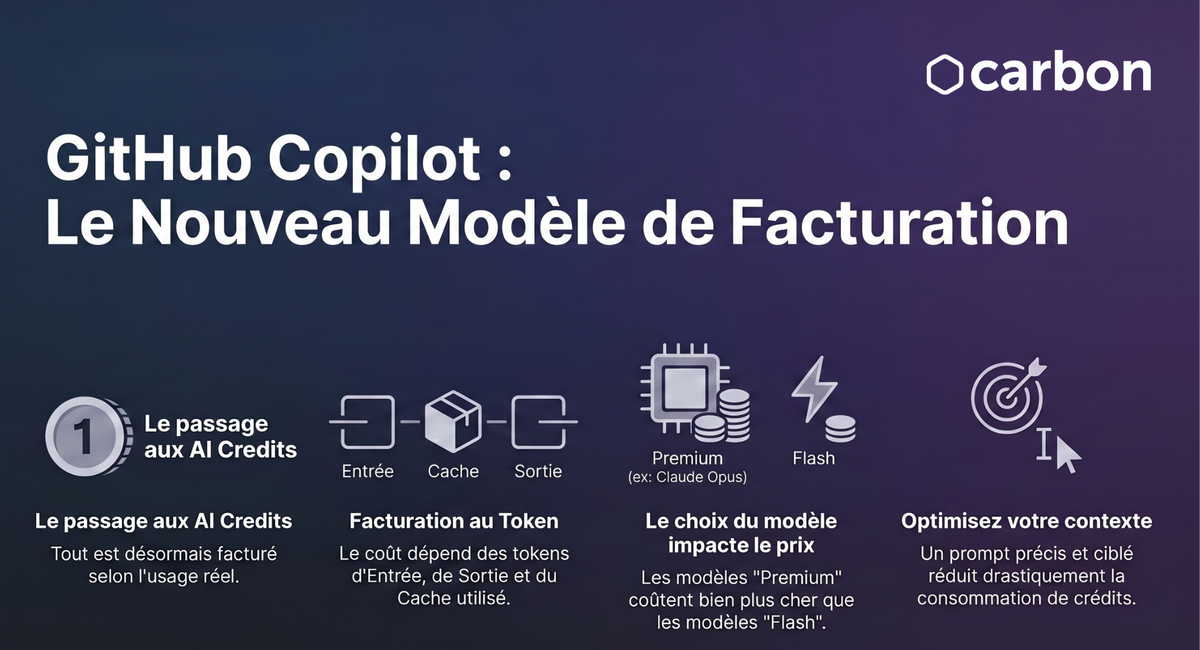
Autrefois facturé en premium request, GitHub Copilot est désormais passé à une logique de coût en AI Credits.
C’était quoi une “Premium Request” (PR) ?
Les bases
Une premium request (PR) était l’unité de mesure principale de l’ancien modèle de facturation. Le prix réel d’une premium request était de 0,04 $.
1 message = X premium requestsDans ce calcul, le X représente le multiplicateur associé au modèle choisi. Plus le modèle était puissant, plus ce multiplicateur était élevé.
Multiplicateurs PR de l'ancien modèle
| Modèle | Multiplicateur PR | Prix réel d'un message |
|---|---|---|
| Grok-Code-Fast-1 | 0 | 0$ |
| Gemini 3 Flash | 0,33 | 0,0132$ |
| Gemini 2.5 Pro | 1 | 0,04$ |
| Gemini 3 Pro | 1 | 0,04$ |
| Gemini 3.1 Pro | 1 | 0,04$ |
| Gemini 3.5 Flash | 14 | 0,56$ |
| GPT-4o mini | 0 | 0$ |
| GPT-5.4 mini | 0,33 | 0,0132$ |
| GPT-5.3-Codex | 1 | 0,04$ |
| GPT-5.4 | 1 | 0,04$ |
| GPT-5.5 | 7,5 | 0,30$ |
| Claude Opus 4.8 | 15 | 0,60$ |
| Claude Opus 4.7 | 7,5 | 0,30$ |
| Claude Opus 4.6 | 3 | 0,12$ |
| Claude Sonnet 4.6 | 1 | 0,04$ |
| Claude Haiku 4.5 | 0,33 | 0,0132$ |
Avec ce système, si l’on prenait le modèle Claude Opus 4.6 :
Bonjour= 3 premium requests = 0,12 $Créer une application front/back avec une architecture microservices et un service de paiement pour [...]. Ajoute des chats en bas de page.= 3 premium requests = 0,12 $
C’était un système simple et facile à comprendre, mais il apportait très peu de visibilité sur la consommation réelle de tokens.
Le changement de paradigme : facturation à l'usage
Tout a changé fin avril 2026, lorsque GitHub a annoncé : "GitHub Copilot is moving to usage-based billing".
Depuis le 1er juin 2026, GitHub Copilot utilise un système de facturation directement à l’usage, aligné sur les tarifs API publiés par les fournisseurs de modèles comme OpenAI, Anthropic ou Google.
La justification de GitHub est limpide :
« Aujourd’hui, une simple question posée en chat et une session de codage autonome de plusieurs heures peuvent coûter le même prix à l’utilisateur »
L’entreprise a longtemps absorbé l’explosion des coûts d’inférence liée aux usages agentiques, mais juge le modèle des premium requests comme n'étant « plus viable ».
La facturation à l’usage vise à aligner le prix sur la consommation réelle.
GitHub Copilot utilise le terme « AI Credits ».
1 AI Credit = 0,01 $
Pour les abonnements

- Les prix de base ne bougent pas.
- Pro 10 $/mois,
- Pro+ 39 $/mois,
- Business 19 $/utilisateur/mois,
- Enterprise 39 $/utilisateur/mois.
- Chaque plan inclut désormais un montant équivalent en IA Credits mensuels.
- Les complétions de code et les suggestions restent gratuites.
Tableau des prix
Ces tarifs sont exprimés pour 1 million de tokens.
1 $ = 100 AIC
| Modèle | Entrée | Sortie | Cache |
|---|---|---|---|
| GPT-5.5 1M | 1000 AIC / 10$ | 4500 AIC / 45$ | 100 AIC / 1$ |
| GPT-5.5 | 500 AIC / 5$ | 3000 AIC / 30$ | 50 AIC / 0.5$ |
| GPT-5.4 1M | 500 AIC / 5$ | 2250 AIC / 22.5$ | 50 AIC / 0.5$ |
| GPT-5.4 | 250 AIC / 2.5$ | 1500 AIC / 15$ | 25 AIC / 0.25$ |
| GPT-5.3-Codex | 175 AIC / 1.75$ | 1400 AIC / 14$ | 17 AIC / 0.17$ |
| GPT-5.4 mini | 75 AIC / 0.75$ | 450 AIC / 4.5$ | 7 AIC / 0.07$ |
| GPT-5 mini | 25 AIC / 0.25$ | 200 AIC / 2$ | 2 AIC / 0.02$ |
| Claude Opus 4.8 | 500 AIC / 5$ | 2500 AIC / 25$ | 50 AIC / 0.5$ |
| Claude Opus 4.7 | 500 AIC / 5$ | 2500 AIC / 25$ | 50 AIC / 0.5$ |
| Claude Opus 4.6 | 500 AIC / 5$ | 2500 AIC / 25$ | 50 AIC / 0.5$ |
| Claude Opus 4.5 | 500 AIC / 5$ | 2500 AIC / 25$ | 50 AIC / 0.5$ |
| Claude Sonnet 4.6 | 300 AIC / 3$ | 1500 AIC / 15$ | 30 AIC / 0.3$ |
| Claude Sonnet 4.5 | 300 AIC / 3$ | 1500 AIC / 15$ | 30 AIC / 0.3$ |
| Claude Haiku 4.5 | 100 AIC / 1$ | 500 AIC / 5$ | 10 AIC / 0.1$ |
| Gemini 3.1 Pro 1M | 400 AIC / 4$ | 1800 AIC / 18$ | 4 AIC / 0.04$ |
| Gemini 3.1 Pro | 200 AIC / 2$ | 1200 AIC / 12$ | 2 AIC / 0.02$ |
| Gemini 3.5 Flash | 150 AIC / 1.5$ | 900 AIC / 9$ | 15 AIC / 0.15$ |
| Gemini 2.5 Pro | 125 AIC / 1.25$ | 1000 AIC / 10$ | 12 AIC / 0.12$ |
| Gemini 3 Flash | 50 AIC / 0.5$ | 300 AIC / 3$ | 5 AIC / 0.05$ |
C'est quoi le calcul ?
Le principe est simple : chaque interaction avec GitHub Copilot consomme des tokens.
Un token est la plus petite unité de texte qu’un LLM manipule (un mot, un morceau de mot, un espace ou un signe de ponctuation).
- En anglais : 1 mot ≈ 1,3 tokens
- En français : 1 mot ≈ 1,7 tokens
- Tokens d’entrée : tout ce que vous envoyez au modèle (prompt, extraits de code, contexte du dépôt, historique de conversation).
- Tokens de sortie : tout ce que le modèle génère en retour.
- Tokens de cache : une partie du contexte déjà traité, réutilisée à tarif réduit dans la suite des échanges.
Un exemple basique
Prenons un exemple avec Claude Opus 4.8 :
- 5 $ / 1 million de tokens d’entrée
- 25 $ / 1 million de tokens de sortie
- 0,5 $ / 1 million de tokens de cache
Imaginons une interaction pour lui demander la météo.
Peux-tu me dire quel temps il fait en France ?
10 mots = 17 tokens = 0,000085 $
Il fait beau en France, voulez-vous que je vous préconise une tenue pour la semaine ?
15 mots = 25 tokens = 0,000625 $
Coût total = 0,000085 $ + 0,000625 $ = 0,00071 $
Et dans le développement ?
L'exemple détaillé est disponible en annexe (fin de l'article).
Restons avec le modèle Opus, avec un agent de code du type GitHub Copilot, et prenons une tâche simple : modifier un fichier de code.
L'Agent IA a besoin de 3 appels pour faire ce changement.
| Modèle | INPUT | OUTPUT | CACHE |
|---|---|---|---|
| Appel 1 | 3 100 T / 0,0155 $ | 1 100 T / 0,0275 $ | 4 200 T / 0,0021 $ |
| Appel 2 | 500 T / 0,0025 $ | 1 500 T / 0,0375 $ | 6 200 T / 0,0031 $ |
| Appel 3 | 80 T / 0,0004 $ | 250 T / 0,00625 $ | - |
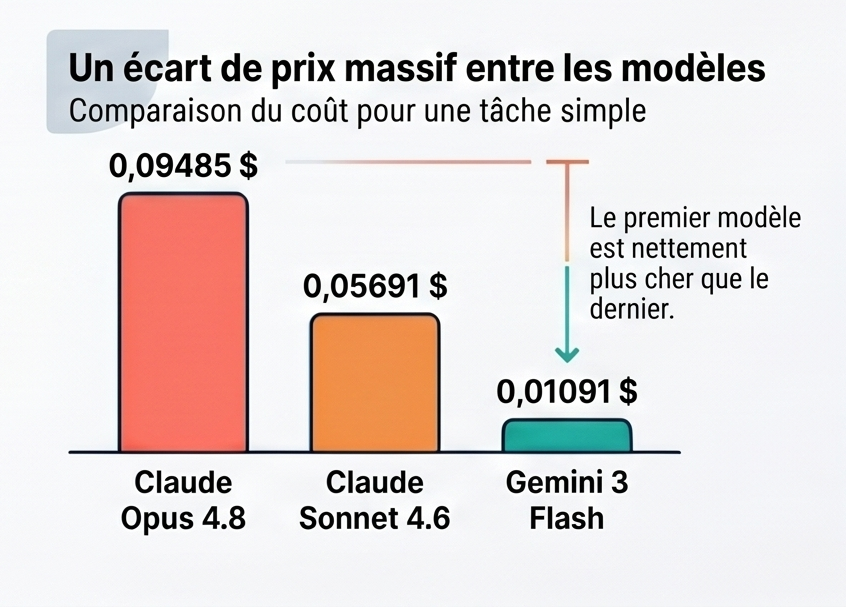
Total : 0,09485 $
Autrement dit, une tâche qui paraît banale, comme lire un fichier, réfléchir à la modification, écrire le correctif puis répondre à l'utilisateur, peut déjà approcher les 10 centimes sur un modèle premium comme Claude Opus 4.8.
Si l'on rejoue exactement le même scénario avec d'autres modèles, on obtient ceci :
| Modèle | Appel 1 | Appel 2 | Appel 3 | Total |
|---|---|---|---|---|
| Claude Opus 4.8 | 0,04300 $ | 0,04210 $ | 0,00975 $ | 0,09485 $ |
| Claude Sonnet 4.6 | 0,02580 $ | 0,02526 $ | 0,00585 $ | 0,05691 $ |
| GPT-5.4 | 0,02425 $ | 0,02480 $ | 0,00550 $ | 0,05455 $ |
| Gemini 3 Flash | 0,00485 $ | 0,00496 $ | 0,00110 $ | 0,01091 $ |
À l'échelle d'une journée de développement, l'écart entre un modèle « premium » et un modèle « léger » peut devenir très significatif.
Nouveaux enjeux
Le basculement vers une facturation au token change profondément la manière d'utiliser GitHub Copilot. Avant, une requête complexe et une requête triviale pouvaient coûter la même chose.
Désormais, le coût dépend directement de trois variables : la taille du contexte envoyé, la quantité de texte générée et le nombre d'itérations nécessaires pour terminer la tâche.
Cela oblige les développeurs à raisonner autrement :
- un modèle puissant n'est plus automatiquement le bon choix ;
- un prompt flou coûte plus cher qu'un prompt précis ;
- un agent mal cadré peut brûler beaucoup de tokens en lectures inutiles, en raisonnement excessif ou en boucles d'outils ;
- un grand contexte n'est pas gratuit, même s'il aide parfois le modèle à mieux répondre.
Bonnes pratiques pour maîtriser les coûts : côté utilisateur
Choisir le bon modèle
Le premier réflexe à adopter est simple : ne pas utiliser le modèle le plus cher par défaut.
Dans beaucoup de cas, un modèle intermédiaire ou léger suffit largement pour :
- reformuler un texte ;
- écrire des tests simples ;
- expliquer un extrait de code ;
- générer un petit patch localisé ;
- produire de la documentation technique.
Réservez les modèles premium aux cas où leur surcoût est justifié :
- refactoring complexe ;
- analyse d'architecture ;
- débogage difficile ;
- raisonnement multi-fichiers ;
- tâches longues avec plusieurs étapes.
Réduire le contexte envoyé
Dans un système facturé au token, le contexte est une ligne de coût à part entière.
Quelques réflexes ont un impact immédiat :
- n'activer que les MCP réellement utiles à la tâche ;
- fournir directement le ou les fichiers concernés quand c'est possible ;
- indiquer un chemin, une fonction ou une classe précise plutôt que « regarde tout le repo » ;
- donner la stack, le framework et l'objectif dès le premier message ;
- découper une grosse demande en étapes courtes et ciblées ;
- éviter les copier-coller massifs de logs ou de fichiers entiers si quelques extraits suffisent.
Autrement dit, plus vous faites le travail de cadrage en amont, moins le modèle gaspille de tokens à explorer, inférer et revenir en arrière.
Adapter le niveau d'effort à la tâche
Quand un modèle propose des niveaux d'effort (low, medium, high, xhigh, voire max), il faut les voir comme un curseur de profondeur de raisonnement.
- low : rapide et économique, idéal pour les tâches simples ou répétitives ;
- medium : bon compromis entre vitesse, coût et qualité ;
- high : adapté aux vrais problèmes de code ou d'analyse ;
- xhigh / max : à réserver aux longues sessions agentiques ou aux cas très difficiles.
Le piège classique consiste à laisser high ou max partout. Le modèle réfléchit davantage, appelle parfois plus d'outils, génère plus de texte intermédiaire et consomme donc plus de tokens. Pour une tâche triviale, c'est souvent de la dépense inutile.
Bonnes pratiques pour maîtriser les coûts : côté gestionnaire
Les utilisateurs GitHub Copilot vont voir leur coût GitHub Copilot subir un multiplicateur énorme. Certains utilisateurs partagent même des x1000 !
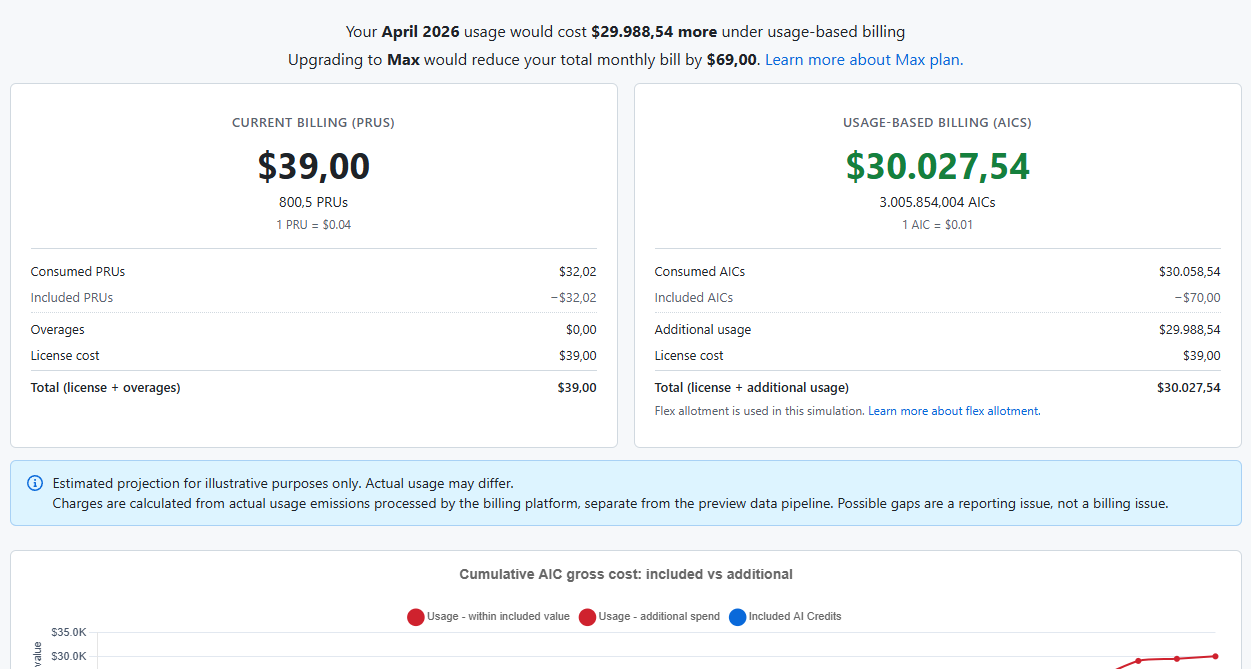
Le système de premium request pouvait permettre à un Agent Opus de tourner des dizaines de minutes pour seulement 0.12$ et de consommer des millions de tokens !
Les entreprises sont en première ligne sur cet enjeu de maîtrise des coûts.
Définir un budget

L'entreprise peut :
- Fixer un budget par utilisateur
- Fixer un budget global (pool pour l'ensemble des utilisateurs)
Créer des profils d'usage
Tous les utilisateurs n'ont pas les mêmes besoins. Il est donc pertinent de définir plusieurs profils :
- advanced user : utilisateur qui maîtrise l'usage des outils IA
- power users : utilisateurs qui utilisent intensivement les agents ;
- one-man army : utilisateur qui remplace une équipe
L'idée n'est pas de "brider tout le monde pareil", mais d'allouer le budget là où le retour sur investissement est le meilleur.
Utiliser les contrôles natifs de GitHub
GitHub permet l'utilisation d'outils de gouvernance :
- budgets au niveau entreprise, team et utilisateur ;
- notifications à l'approche des seuils ;
- mutualisation des crédits inclus entre utilisateurs ;
- choix d'autoriser ou non la consommation additionnelle une fois le pool inclus épuisé.
Ces mécanismes sont précieux, car ils évitent à la fois le gaspillage des crédits inutilisés et les dépassements silencieux.
Former les équipes au token-based pricing
Le meilleur contrôle budgétaire reste la pédagogie.
Former les équipes à quelques notions simples — différence entre tokens d'entrée et de sortie, rôle du cache, impact du niveau d'effort, coût d'un grand contexte — suffit déjà à faire baisser fortement la consommation inutile.
Un développeur qui comprend comment sa session est facturée écrit en général de meilleurs prompts, choisit mieux ses modèles et coupe plus vite les workflows inefficaces.
Stratégies d’optimisation avancées
Au-delà des réglages natifs et des bonnes pratiques individuelles, on peut industrialiser la maîtrise des coûts. Quatre grandes stratégies se dégagent :
- Routing intelligent des modèles : aiguiller automatiquement chaque requête vers le modèle le moins cher capable de la traiter, et ne pas utiliser vers un modèle premium qu'en cas d'échec ou de complexité avérée.
- Décomposition des tâches : découper une grosse demande en sous-tâches courtes et ciblées, confiées à des agents ou des modèles légers, plutôt qu'une seule session premium tentaculaire.
- Usage hybride (cheap + smart fallback) : traiter le gros du volume avec un modèle économique et ne basculer sur un modèle puissant que sur les cas où il apporte une vraie valeur.
- Caching des réponses fréquentes : mémoriser les réponses aux requêtes récurrentes pour éviter de les refacturer à chaque fois.
En complément, il existe déjà un écosystème d'outils destinés à compacter, filtrer ou contraindre le contexte envoyé aux LLM.
- RTK : outil open source en Rust, pensé pour épurer le contexte avant envoi au modèle ;
- Snip : alternative en Go avec des règles déclaratives YAML pour garder certains éléments et en couper d'autres ;
- Headroom : approche orientée sélection des informations les plus pertinentes dans les contextes longs ;
- Caveman : plugin ou skill qui force des réponses extrêmement courtes pour réduire les tokens de sortie.
Nous ne les développerons pas davantage ici, car chacune mérite un benchmark sérieux : gain réel en tokens, impact sur la qualité, complexité d'intégration et retour sur investissement.
Conclusion
Le passage des premium requests aux AI Credits n'est pas un simple changement de vocabulaire. Il rapproche GitHub Copilot de la réalité technique des LLM : chaque contexte envoyé, chaque réponse générée et chaque boucle agentique a désormais un prix visible.
Pour les développeurs, cela impose de nouveaux réflexes : mieux choisir ses modèles, mieux cadrer ses prompts, mieux limiter son contexte et mieux surveiller ses sessions.
Pour les organisations, cela ouvre aussi la voie à une gouvernance de l'usage IA, avec budgets, mutualisation et politiques de consommation.
En clair, utiliser un assistant de code ne relève plus seulement de la productivité. C'est aussi, de plus en plus, un sujet d'architecture d'usage et de pilotage des coûts.
Annexe
Exemple dans le développement
Passons à un exemple typique dans le développement. Pour cet exemple, nous n'allons pas détailler précisément les prompts, les mots ni les outils. Nous allons uniquement parler du nombre de tokens.
Restons avec le modèle Opus, avec un agent de code du type GitHub Copilot, et prenons une tâche simple : modifier un fichier de code.
La stratégie de cache utilisée ici est simple : nous conservons les éléments déjà vus par le modèle pour qu'ils soient refacturés moins cher lors des appels suivants. Différentes stratégies de cache existent, mais nous ne nous y attarderons pas ici.
L'utilisateur exprime son besoin dans un prompt.
[system-prompt: 1 500 tokens] // rôle, règles
[built-in tools (description): 500 tokens] // outil intégré à l'agent IA
[mcp github (description): 500 tokens] // outil supplémentaire
[mcp sonarqube (description): 500 tokens] // outil supplémentaire
[user prompt: 100 tokens] // Modifie l'algorithme de la fonction...
Coût de l'entrée : 3 100 × 5 $ / 1 000 000 = 0,0155 $L'agent IA analyse et prépare un plan d'action.
[thinking: 1000 tokens] // analyse de la demande, plan d’action
[call tool built-in.read-file: 100 tokens] // demande de lecture du code
Coût de la sortie : 1 100 × 25 $ / 1 000 000 = 0,0275 $Coût total de l'appel 1 : 0,0430 $[input: 3100]
[output: 1100]
Coût du cache : 4 200 × 0,5 $ / 1 000 000 = 0,0021 $Ce coût sera utilisé pour la lecture du cache au prochain appel.
Déclenché par l'appel à l'outil read-file.
Coût de l'entrée hors cache : 500 × 5 $ / 1 000 000 = 0,0025 $Coût total de l'entrée de l'appel 2 : 0,0046 $L'agent a maintenant le contexte du code et peut appliquer la modification.
[thinking: 1200 tokens] // analyse du fichier et préparation du patch
[call tool built-in.write-file: 300 tokens] // écriture de la modification
Coût de la sortie : 1 500 × 25 $ / 1 000 000 = 0,0375 $Coût total de l'appel 2 : 0,0421 $[cache appel 1 : 4 200]
[input: 500 tokens]
[output: 1 500 tokens]
Coût du cache : 6 200 × 0,5 $ / 1 000 000 = 0,0031 $[cache: 6 200 tokens]
[tool response built-in.write-file: 80 tokens] // confirmation d'écriture
Coût du cache :0,0031 $
Coût de l'entrée hors cache :80 × 5 $ / 1 000 000 = 0,0004 $
Coût total de l'entrée de l'appel 3 : 0,0035 $[final answer: 250 tokens] // résumé des changements effectués
Coût de la sortie : 250 × 25 $ / 1 000 000 = 0,00625 $Coût total de l'appel 3 : 0,00975 $Appel 1 :0,0430 $
Appel 2 :0,0421 $
Appel 3 :0,00975 $
Total : 0,09485 $
Autrement dit, une tâche qui paraît banale, comme lire un fichier, réfléchir à la modification, écrire le correctif puis répondre à l'utilisateur, peut déjà approcher les 10 centimes sur un modèle premium comme Claude Opus 4.8.
Si l'on rejoue exactement le même scénario avec d'autres modèles, on obtient ceci :
| Modèle | Appel 1 | Appel 2 | Appel 3 | Total |
|---|---|---|---|---|
| Claude Opus 4.8 | 0,04300 $ | 0,04210 $ | 0,00975 $ | 0,09485 $ |
| Claude Sonnet 4.6 | 0,02580 $ | 0,02526 $ | 0,00585 $ | 0,05691 $ |
| GPT-5.4 | 0,02425 $ | 0,02480 $ | 0,00550 $ | 0,05455 $ |
| Gemini 3 Flash | 0,00485 $ | 0,00496 $ | 0,00110 $ | 0,01091 $ |
À l'échelle d'une journée de développement, l'écart entre un modèle « premium » et un modèle « léger » peut devenir très significatif.