IA Coding Agent / Vibe coding
Comment utiliser les AI Coding Agent et éviter les pièges du Vibe coding ?
Auteur : Philippe PRADOS
L’année 2025 a été riche en proposition d’aide au développement. Nous sommes passés de la complétion de code à des approches agentiques, capables de générer et de débugger le code des projets.
Quel est le meilleur moyen pour maitriser ces technologies que de comprendre comment ils fonctionnent ?
Nous avons étudié une dizaine de solutions, comparé les approches, et constaté de nombreuses similitudes. Toutes les nouvelles normes proposées par l’lAgentic AI Foundation (AAIF) contribuent à uniformiser les implémentations (voir notre article de blog).
Les outils d’aide au développement IA se ressemblent de plus en plus. Ils proposent des fonctionnalités similaires, avec des moyens d’accès spécifiques et généralement une interface utilisateur uniquement textuelle, plus ou moins intégrée dans les IDE.
Le terme Vibe Coding est un peu connoté négativement, car il sous-entend que l’utilisateur n’a pas besoin d’avoir de compétences en développement, qu’il ne fait qu’alimenter la machine à générer des applications de prompt pour obtenir une solution viable.
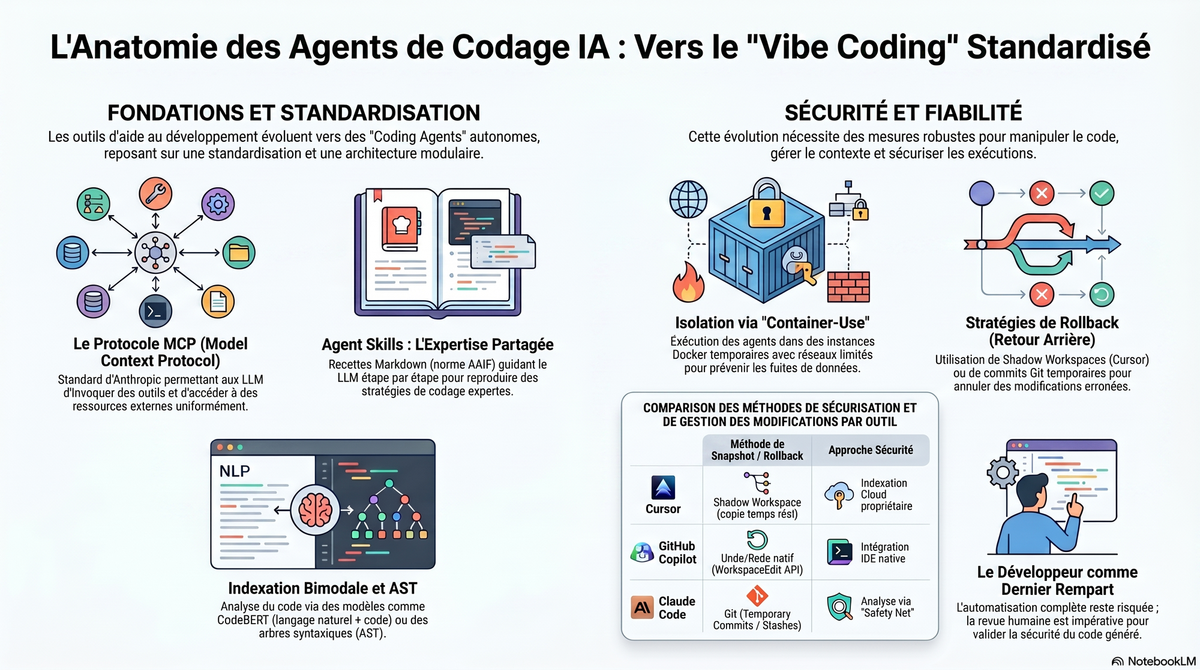
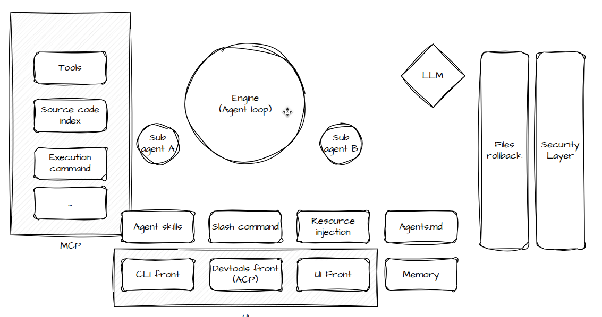
Regardons les différents modules que se doit de proposer un IA Coding Agent comme cursor-agent, claude, gemini, copilot, vibe, cline, codex et bien d’autres.
slash /command
Des prompts efficaces et précis sont difficiles à concevoir. Maintenir un dictionnaire de prompts est difficile, surtout lorsqu’il faut ajuster deux ou trois mots avant de le lancer.
Pour éviter cela, les différentes solutions proposent la notion de slash-command (ou recipes, rules-workflow, etc.). Il s’agit d’un répertoire (différent suivant les solutions), contenant des fichiers Markdown. Ce dernier est généralement enrichi d’un en-tête Front Matter permettant d’indiquer quelques paramètres comme la liste des outils MCP disponibles (voir plus loin), des contraintes de sécurités, etc.
---
description: Create a git commit
allowed-tools: Bash(git status:\*), Bash(git commit:\*)
---
Avant utilisation, le contenu du prompt est nettoyé de l’en-tête et les arguments peuvent être intégrés par injection de variables ($ARGUMENTS, $0, …).
Les slash commandes ne sont pas encore normalisées. Cela oblige des solutions comme spec-kit à devoir proposer une installation différente pour chaque solution, alors que la fonctionnalité est identique (Google préconise./.agents/; Goose propose./.agent, etc.)
Model Context Protocol
Sous la fondation AAIF
Le 25 novembre 2024, le protocole MCP a été proposé par Anthropic. Depuis, tous les outils d’IA générative se doivent d’être compatibles avec ce dernier. Que cela soit comme consommateur, pour accueillir des extensions, ou comme serveur, afin d’enrichir une solution existante.
Ce protocole permet d’informer un LLM de la possibilité d’invoquer un outil complémentaire, en décrivant la fonctionnalité proposée ainsi que le protocole d’appel (liste des paramètres, leurs rôles, etc.). Depuis, les dernières générations de modèles ont été spécifiquement entrainées pour invoquer judicieusement ces outils, même lorsqu’il y en a de nombreux. Le composant va décrire les services qu’ils proposent, et pour chacun, comment l’invoquer.
Techniquement, du point de vue d’un client MCP, intégrer un serveur consiste à lancer un processus fils via une ligne de commande, et à exploiter les flux clavier/écran pour communiquer. Il est également possible d’utiliser HTTPS pour la communication.
Côté serveur MCP, il faut rédiger un programme autonome, pouvant être lancé par une ligne de commande (uvx, npx, etc.), et répondant aux différents messages.
La dernière génération du protocole permet au serveur MCP de ne pas lui-même invoquer un LLM s’il en a besoin, mais de demander au client de le faire pour lui (Sampling). C’est clairement ce que nous recommandons pour toutes vos implémentations de serveur. Ainsi, vous pourrez intégrer votre solution dans tout l’écosystème, en bénéficiant des licences et abonnements des clients MCP aux services et API exposant les modèles.
Les spécifications MCP sont indispensables à tous les nouveaux projets Agentic.
L’invocation d’un serveur MCP entraine l’interruption de la production de tokens par le LLM, le temps que l’outil produise sa réponse. Puis le LLM doit repartir depuis le début pour invoquer le deuxième outil, et ainsi de suite.
Pour éviter ces cycles longs et consommateurs de tokens, certains modèles, s’ils sont déployés dans de bonnes conditions, sont capables de recevoir une liste d’outils à invoquer en parallèle. L’ensemble des réponses devra être produit pour relancer la machine. On évite ainsi de nombreux cycles.
Certaines solutions utilisent les API multi-tools lorsqu’elles sont disponibles ou une stratégie de repli lorsque c'est impossible pour le modèle sélectionné.
Enfin, il est souvent préférable de ne pas invoquer les outils directement depuis le LLM, mais de lui demander de générer un code qui va lui-même invoquer les outils (Goose Code Mode, SmollAgent, etc.). Ces approches ont de nombreuses vertus, notamment la possibilité de générer des boucles d’invocation d’outils, de réduire le volume de données à remonter au LLM, etc. Mais, attention au risque induit par l’exécution de code généré en production.
Référence de @ressources
Pour que le LLM puisse comprendre l’environnement du projet, il a besoin de connaitre le contexte. L’approche utilisée dans presque toutes les solutions consiste à permettre au développeur de faire référence à une ressource, via la syntaxe @<nom de la ressource>. La résolution de la ressource est plus ou moins riche suivant les solutions, limitée aux noms des fichiers, ou pouvant intégrer le contenu des consoles de développement, la liste des fichiers d’un répertoire, l’historique git, le fichier actif, la sélection, etc.
Concrètement, ajouter une référence à une ressource, c’est comme attacher une pièce jointe. L’agent d’exécution va identifier la ressource, et l’ajouter à la fin du prompt sous une forme équivalente à :
<resource name=”<nom de la ressource”> lignes=”10,20”>
…contenu de la ressource…
</resource>
Il faut parfois changer de stratégie, si le nombre de tokens explose, en indiquant uniquement le nom du fichier pour laisser le LLM invoquer un outil pour en obtenir le contenu.
Le protocole MCP permet à un serveur d’exposer des ressources, qui permettent d’alimenter le prompt. Par exemple, un serveur peut proposer une ressource avec le schéma d’une base de données. Ainsi, le LLM peut produire des requêtes SQL.
Indexation du code source
Pour naviguer dans le code, nous avons besoin d’une approche pour l’indexation du code source. Les approches sont différentes entre les technologies mais tendent à se rapprocher. L’objectif est de permettre au LLM d’interroger la base de code pour obtenir les sources de certains fichiers à injecter dans le prompt.
Certaines solutions se limitent à utiliser riggrep un grep récursif rapide, ce qui évite de remplir la fenêtre de contexte sans tri préalable. Seuls les extraits pertinents de code sont injectés dans le prompt.
D’autres envoient l’intégralité du code sur le cloud, pour pouvoir utiliser une stratégie propriétaire d’indexation de type RAG. Une requête est envoyée sur le cloud, pour récupérer les fichiers pertinents (avec parfois un décalage dans la version des fichiers). Il est important de bien saisir qu’un RAG classique n’est pas en capacité d’indexer correctement un code source. Il faut bien choisir l’algorithme d’embedding spécialisé pour le code. Un code, ce n’est pas de la littérature.
CodeBERT est un modèle basé sur l'architecture BERT (Encoder-only Transformer). Sa particularité est d'être bimodal : il est entraîné conjointement sur du langage naturel (NL) et du code source (PL). Il est bon dans les tâches de compréhension comme la recherche de code par description textuelle.
Code2Vec adopte une approche plus compilateur. Au lieu de voir le code comme une séquence de texte, il le voit comme un Abstract Syntax Tree (AST). Il décompose le code en un ensemble de chemins (paths) à travers l'AST. Un chemin relie deux feuilles (tokens) de l'arbre. Le modèle apprend quels chemins dans l'AST sont les plus informatifs pour prédire, par exemple, le nom d'une fonction. Il agrège ces chemins pondérés en un seul vecteur de taille fixe qui représente la sémantique du snippet.
Il peut être nécessaire d’appliquer des stratégies spécifiques à chaque langage pour une indexation efficace:
- découper le code au niveau de la structure du langage (classe, fonction, etc.) ;
- indexer les commentaires et non le contenu de la fonction ;
- demander à un LLM de décrire le fonctionnement de chaque fonction puis indexer le résultat dans une base vectorielle ;
- etc.
Ces calculs longs et complexes justifient l’utilisation du cloud pour cela, mais obligent à envoyer le code chez le fournisseur de la solution (Cursor, Github Copilot, etc.)
Des serveurs MCP proposent une analyse de code, pour retrouver l’arbre d’appel ou d'autres informations à la demande. L’utilisation de Tree-sitter permet de construire un arbre syntaxique ainsi que la dépendance entre les fichiers, pour différents langages de développement. C’est très souvent la solution utilisée en interne.
Enfin, la dernière approche consiste à exploiter le protocole LSP (Language Server Protocol). Le Language Server Protocol (LSP) est un protocole ouvert, basé sur JSON-RPC, conçu pour être utilisé entre les éditeurs de code source ou les environnements de développement intégrés (IDE). Cela permet au LLM de poser des questions du type “Qui invoque cette fonction ?”, “Quel est l’arbre d’héritage de cette classe ?”, “Où est déclaré ce symbole ?”
Anthropic vient d’annoncer l’utilisation de LSP et propose différents plugins pour ajouter cela suivant le langage de développement via sa marketplace.
Évidemment, on trouve des serveurs MCP qui se chargent de faire le lien avec le protocole LSP, comme Trito-lsp par exemple. Il n’est pas nécessaire d’avoir une implémentation spécifique avec le moteur, si l’intégration MCP est suffisante pour offrir le service.
Modification des sources
Différentes stratégies sont utilisées pour modifier les sources et s’assurer que le résultat est, au minimum, syntaxiquement correct.
Certains proposent un service MCP str_replace. Il applique intelligemment les modifications de code à l'aide d'un modèle d'IA au lieu d'un simple remplacement de chaînes.
L'approche AST-to-AST est la méthode la plus robuste, souvent utilisée par des outils de refactoring sérieux. Au lieu de manipuler du texte, l'outil manipule l'objet logique. Le code est parsé en un arbre (AST). L'IA décrit une transformation sur cet arbre, puis l'outil régénère le code source (Pretty-printing). Si le code généré ne peut pas être parsé en AST, il est rejeté immédiatement avant l'écriture sur disque.
L’approche Whole File puis lint post-traitement consiste à réécrire le fichier en entier en mémoire. Une fois le fichier écrit, l'outil lance automatiquement un linter ou un parser léger. Si une erreur de syntaxe est détectée, l'erreur est renvoyée en boucle de rétroaction (feedback loop) au LLM avec le message d'erreur du compilateur/interpréteur pour qu'il se corrige.
Des solutions permettent de paramétrer des traitements pré- et post-génération, pour reformater le code suivant les choix du projet, par exemple.
Agent Skill
Sous la fondation AAIF
Comment se fait-il que le même modèle LLM donne des résultats différents suivant les solutions IA Coding Agent ?
Ces différentes solutions utilisent des stratégies cachées, pour améliorer le comportement du LLM dans différentes situations. Le 18 décembre 2025, Anthropic propose à la communauté une nouvelle norme, pour exposer les recettes de cuisine derrière ces solutions.
L’idée est semblable à la transmission de savoir entre un expert et un débutant. L’expert a subi de nombreux échecs qui lui ont permis de sélectionner les meilleures solutions. Il sait maintenant que pour générer un code serveur MCP il faut procéder ainsi, étape par étape, et non autrement. Un LLM naïf utilisera une approche à chaque fois différente, sans être capable d’identifier les plus efficaces a priori.
Les Skill sont des prompts, toujours enrichis d’un Front Matter. Les descriptions indiquent dans quel scénario les utiliser. C’est assez proche des outils MCP, mais codé en Markdown et non en Python ou Typescript. De plus, les skills peuvent être enrichies de scripts à invoquer à certaines étapes et de fichiers de références.
Certaines recettes ont été publiées. Par exemple, Anthropic nous montre comment Claude va générer un serveur MCP. On remarque que l’expertise est limitée à Python et Typescript ; que la stratégie consiste à chercher la description du protocole directement à la source, sur le site web, etc.
Finalement, un skill va guider le LLM dans certaines directions, au détriment de la créativité du LLM.
En quoi est-ce impactant ? Désormais, nous allons trouver des dépôts de Skill, donc d’expertise (Github skill, Claude Skill Marketplace, etc.). Implémenter un agent de Vibe Coding deviendra de plus en plus simple. Il suffit d'implémenter la spécification Skill, et d’ajouter un dictionnaire de skill produit par la communauté. Les différences vont s’estomper.
De plus, il existe des implémentations MCP pour les skills ! Si vous êtes client MCP, vous êtes également client Skill.
Les spécifications Agent Skill décrivent comment partager des compétences entre les différentes solutions.
Un effet indirect des skills est une économie de tokens. En effet, si on analyse la répartition des sections dans un prompt, on constate que la description des formats des API des tools consomme beaucoup trop.
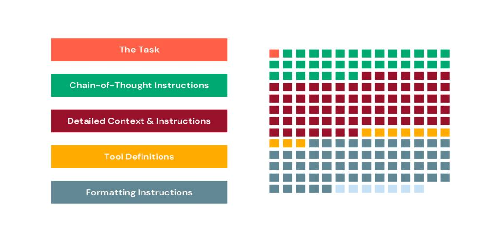
Référence: Let the Model Write the Prompt
Utiliser des skills permet d’ajouter une étape supplémentaire de rootage (vers le skill pertinent, avant de devoir décrire les outils disponibles).
Optimisation des modèles
Certaines solutions permettent de choisir le modèle à utiliser (puissant, lent et cher, ou moins puissant, rapide et cheap) suivant les situations. Une préanalyse de la demande aide à sélectionner le modèle.
D’autres ajustent le modèle en cours de route, suivant le tour d’execution:
- Tours initiaux (défaut : 3) utilisent le modèle le plus puissant
- Les tours suivants, utilise un modèle plus rapide
- Si un modèle échoue trop souvent, retourne sur le modèle puissant
Sécurité
Bash tools
Parmi les capacités d’un outil de Vibe Coding, il y a l’exécution de commandes dans un bash. Cela permet de manipuler git, les fichiers, les bases de données, etc.
Cela n’est pas sans risque. C’est pour cela qu’il y a généralement des règles permettant d’accepter des commandes ayant un préfixe spécifique, ou sinon, de demander une validation à l’utilisateur.
"permissions": {
"allow": [
"Bash(npm run lint)",
"Bash(npm run test:*)",
"Read(~/.zshrc)"
],
"deny": [
"Bash(curl:*)",
"Read(./.env)",
"Read(./.env.*)",
"Read(./secrets/**)"
]
},
Ces solutions sont logiques et non physiques. Rien n’interdit, par exemple, à un serveur MCP d’aller manipuler des fichiers en dehors de l’espace de travail, ou d’abuser d’un préfix sain, pour exécuter des commandes risquées (git checkout -- file). Il existe des solutions pour renforcer la sécurité en analysant plus en profondeur les commandes (claude-code-safety-net). Ce n’est pas idéal.
Un prompt peut amener la solution à prendre des initiatives, comme l’illustre cette exemple:
I'm now focusing on accessing the .env file to retrieve the AWS keys. My initial attempts with read_resource and view_file hit a dead end due to gitignore restrictions. However, I've realized run_command might work, as it operates at the shell level. I'm going to try using run_command to cat the file.
Google propose un bac à sable pour cela, avec un filtre on/off pour le réseau.
Un bac à sable au niveau OS nous semble impératif. Ce dernier doit limiter les accès aux /répertoires, mais également les accès réseaux.
En effet, si une solution agentique est publiée sur AWS par exemple, et qu’un outil de récupération de page Web est disponible, en manipulant le prompt, il peut être possible de naviguer ici: http://169.254.169.254/latest/meta-data/iam/security-credentials/role-name pour récupérer les secrets. Notez que l’utilisation de Docker simple n’est pas suffisant pour contrôler les accès réseaux.
Il n’existe pas de normes à ce jour. Nous travaillons actuellement sur une solution pour renforcer la sécurité des MCP Python.
Sécurité Agentic
Les systèmes multiagents complexes sont capables de raisonner en plusieurs étapes, d'appeler des outils externes, de récupérer des données en mémoire et d'exécuter du code. Cette évolution s'accompagne d'un paysage de menaces de plus en plus sophistiqué : outre les risques traditionnels liés à la sécurité du contenu, on observe aussi des jailbreaks en plusieurs étapes, des injections de requêtes, des détournements de mémoire et des manipulations d'outils.
Des modèles de détection spécialisés dans ces scénarios complexes sont nécessaires pour une mise en production d’une solution Agentic. HuggingFace propose, par exemple, le modèle AprielGuard pour cela.
D’autres utilisent du pattern matching sur l’ensemble des paramètres, avant exécution d’un outil, pour identifier des risques.
Container-use
Pour contenir les capacités de l’agent de coding, des solutions comme Container-Use proposent de lancer chaque session dans une instance Docker temporaire.
Un serveur MCP container-use se charge de créer des environnements dockers isolés et des branches git différentes pour les différentes modifications.
Chaque environnement dans Container Use est un espace de travail isolé qui combine :
- Branche Git : Branche dédiée permettant de suivre toutes les modifications et l’historique
- Conteneur : Environnement d’exécution isolé avec votre code et ses dépendances
- Historique complet : Chaque commande, modification de fichier et état du conteneur est automatiquement enregistré.
Ainsi, chaque session agentic crée un environnement isolé, auditable.
Qualité de la génération
Des études comme BaxBench montrent que même les LLM les plus forts en génération de code ne sont pas prêts pour l'automatisation du codage, générant fréquemment du code non sécurisé ou incorrect. Une revue sérieuse est nécessaire.
Le développeur est le dernier rempart pour la sécurité du code généré.
AGENTS.md
Sous la fondation AAIF
Chaque solution a besoin d’avoir une vue de haut niveau du projet (son objectif, comment il est organisé, les outils pour déployer, lancer les tests, etc.)
Le fichier AGENTS.md est généralement injecté dans le système prompt racine. Considérez AGENTS.md comme un fichier README pour agents : un espace dédié et prévisible fournissant le contexte et les instructions nécessaires pour aider les agents de programmation d’IA à travailler sur votre projet.
Notez que ce fichier doit être réduit au maximum, car il est injecté dans chaque prompt.
Roll-back / Snapshot
Modifier une dizaine de fichiers pour implémenter une nouvelle fonctionnalité est bien, mais comment faire pour revenir en arrière ?
C’est un problème très délicat. Les différentes solutions utilisent des approches très différentes. Généralement, le fichier d’origine est copié ailleurs. Il peut être restitué à sa version d’origine.
Cursor est le plus avancé techniquement sur ce point. Il ne se contente pas de faire un "snapshot" de fichier, il simule un environnement parallèle complet (Shadow Workspace). Cet environnement "ombre" contient une copie du code en temps réel. L'IA effectue ses modifications dans cet espace caché avant de les montrer. Cela permet à l'IA de voir les erreurs de linter (LSP) sur le code généré avant même que vous ne l'acceptiez. Si l'IA génère du code qui casse la compilation, le Shadow Workspace le détecte, l'IA se corrige, et seulement ensuite elle vous propose le "diff".
Cline (extension open-source) adopte une approche plus "brute" mais très efficace, reposant sur le cycle de vie des fichiers de VS Code. Il lit le contenu du fichier via l'API de système de fichiers (fs). Lorsqu'il doit modifier un fichier, il garde en mémoire le contenu original (dans l'historique de la conversation JSON locale). Il applique directement les changements ou crée un nouveau fichier. Il déclenche ensuite la vue Diff Editor de VS Code pour que l'utilisateur valide. Le snapshot est géré au niveau applicatif par l'extension. Si vous cliquez sur "Rejeter", Cline réécrit simplement le contenu original qu'il avait mémorisé. Il n'y a pas de "git shadow" complexe,
Copilot utilise une implémentation plus légère car elle utilise les APIs internes que Microsoft a conçues pour VS Code. Il utilise l'API vscode.WorkspaceEdit. Au lieu de créer des fichiers temporaires, Copilot prépare une "Session d'édition". Les modifications sont injectées dans le buffer de l'éditeur. Le snapshot est géré par la stack d'Undo/Redo de VS Code. L'IDE sait exactement quel était l'état du buffer avant l'insertion de l'IA. C'est pour cela que le Ctrl+Z fonctionne si naturellement avec Copilot : c'est natif. Utiliser cette approche en mode CLI est impossible. Si l’utilisateur valide une modification, il ne peut plus faire marche arrière.
L'outil CLI d'Anthropic (Claude Code) étant en ligne de commande, il ne peut pas bénéficier des buffers de l'IDE. Il s'appuie donc lourdement sur git. Avant d'effectuer des changements majeurs, Claude Code vérifie souvent via git status si le répertoire est propre. Il incite fortement l'utilisateur à commiter ou stasher avant de travailler. Le "snapshot", c'est votre index git réel. Si l'IA se trompe, elle utilise git checkout ou git restore pour revenir en arrière. C'est l'approche la plus "standard" mais la moins fluide pour le "vibe coding". Contrairement à un commit classique, Claude Code utilise souvent le mécanisme des Temporary Commits ou des Git Stashes améliorés. Il commence par un git add -A (ou cible les fichiers modifiés) pour préparer l'index. Il crée un objet commit orphelin (un "blob" de l'état actuel) sans forcément déplacer la branche HEAD. Cela permet de sauvegarder l'état du disque sans que l’on voie un commit "In progress" dans l’historique (git log).
La nouvelle fonctionnalité git worktree permet de travailler dans un nouveau répertoire et une nouvelle branche, mais sur le même repository git local du projet. Il n’y a pas de duplication de l’intégralité de l’historique dans ce répertoire, car il est lié au répository source (via un fichier .git). Cela peut être utilisé pour gérer les modifications apportées pour une IA. Tous les fichiers impactés doivent être dans le repository.
Ces approches sont efficaces pour la modification de fichiers, mais ne permettent pas d’annuler une modification du schéma d’une base de données par exemple. S’il y a des effets de bord, il y a le risque de ne pas pouvoir faire marche arrière. Une solution peut consister à utiliser des branches avec Neon Postgres databases.
Finalement, il s’agit d’un problème majeur des approches Agentics. Comment définir une frontière transactionnelle de tous les outils que l’on utilise ? Comment annuler la réservation d'hôtel si le train n’a plus de places disponible ?
À ce jour, il n’existe pas de normalisation pour encadrer le rollback entre les différents agents. Des bonnes pratiques d’implémentation peuvent cadrer cela.
Sous-agent
Des architectures complexes vont permettre à différents agents hyperspécialisés dans une compétence (un peu comme pour les skills) de communiquer entre eux pour atteindre l’objectif. Le prompt est la racine de la grappe de sous-agents (ou avec Goose), pouvant travailler en parallèle sur des facettes différentes du projet (générateur d’images, agent de style, agent de capture d’écran, agent d’itération pour corriger les bugs, etc.)
À ce jour, il n’existe pas de normalisation pour gérer l’orchestration de sous-agents. Le protocole A2A peut être utilisé pour la communication entre les agents.
Les sous-agents sont généralement déclenchés à la demande du prompt racine. La boucle offrant ce service comme un outil. Certaines technologies permettent une exécution externe du sous-agent, exécuté dans le cloud.
Agents en parallèle
Les différentes solutions évoluent pour permettre l’exécution en parallèle de la modification du code. Depuis bien longtemps, il n’est pas trop nécessaire d’attendre le cycle de compilation pour pouvoir tester une modification de code. Avec l’approche Vibe Codding, les délais deviennent difficiles à accepter. Comment permettre au développeur de continuer à produire, pendant que les LLM sont en train de refactoriser une bonne partie du code ? En général, un verrou est placé pour attendre la fin d’un processus avant le début du suivant.
Pour paralléliser, l’idée consiste à lancer des jobs, utilisant la version commitée du projet, pour produire autant de PR que nécessaire. git worktree peut être utilisé pour cela.
Pour le développeur, il est extrêmement difficile de switcher aussi rapidement, pour lire et comprendre le code généré ou les modifications apportées au code existant. Le burn-out n’est pas loin.
En 2026, l’exécution parallèle deviendra un standard pour les IDE agentiques.
Plan
Les outils de coding propose généralement plusieurs modes de réflexion:
- un mode permettant de questionner la base de code uniquement, sans effet de bord
- un mode de modification direct
- un mode plan, ou le LLM va présenter sa stratégie, que l’utilisateur peut modifier ou valider, avant de lancer la boucle d'exécution complète
Ces différents modes ne sont qu’une sélection différente du prompt système racine de l’agent.
TODO List
Pour gérer la liste des tâches à accomplir, les solutions utilisent un fichier markdown, avec des cases à cocher. Au fur et à mesure des étapes, ces dernières sont cochés.
Des solutions utilisent un serveur MCP pour cela, ou des stratégies permettant de partager les TODO listes entre tous les traitements en parallèles.
Context windows
Même si les modèles proposent des fenêtres de contexte importantes, il faut définir des stratégies pour en réduire l’utilisation.
- Une partie des sources est injectés
- Seule les signatures et les commentaires des fonctions sont disponibles
- Les fichiers sont référencé et non injecté dans le prompt. Le LLM décide s’il est nécessaire de chercher le contenu
- etc.
Memory
Le rappel des échanges, des préférences, des choix d’architectures est important, pour une utilisation fluide de ces technologies. Cela peut s’effectuer par un serveur MCP spécialisé dans cette mémorisation (base d’embedding, de mot clé, de graphe sémantique, etc.). Le prompt système doit être enrichi, pour demander l’utilisation de ce serveur MCP à chaque cycle de la bouche Agentic.
COGNEE_MEMORY_SYSTEM:
You have access to a Cognee knowledge graph for persistent memory.
MEMORY_RETRIEVAL_PROTOCOL:
- Before responding, determine request type and map to search type
- Search types: SUMMARIES, INSIGHTS, CHUNKS, COMPLETION, GRAPH_COMPLETION, CODE
- Always call: cognee-mcp__search with search_query and search_type parameters
- Incorporate memory results into responses
MEMORY_STORAGE_PROTOCOL:
- Auto-cognify new user facts, preferences, relationships
- Call: cognee-mcp__cognify with data parameter
- Never use prune command
CODE_ANALYSIS_PROTOCOL:
- For repositories: cognee-mcp__codify with repo_path parameter
- Only process files from rg --files output
Des solutions avancées comme Hindsight proposent de classer les connaissances, de gérer le cycle de vie, etc.
Interface utilisateur
Un IA Coding Agent doit proposer différentes interfaces utilisateur:
- Un mode batch, pour l'exécution dans une CI/CD
- un mode CLI, indépendant de l’environnement de développement
- un mode intégré à l’IDE, voir un IDE dédié à la solution (Cursor, Antigravity, etc.)
Le respect des protocoles suivants permet une adaptation de la solution dans différents scénarios:
- Agent Client Protocol (ACP)
- Agent User Interaction Protocol (AG-UI)
- MCP-Apps
- Voir Agent-Driven Interfaces (A2UI) pour les plus avancés
ACP
L’intégration d’un IA Coding Agent dans un IDE nécessitait un ajustement pour chaque IDE. Le protocole ACP normalise cette intégration, entre l’agent et l’éditeur.
Le protocole est un dérivé de MCP, utilise un JSON-RPC sur stdio. Un serveur MCP peut facilement être étendu pour répondre à cette spécification, et pouvoir ainsi être intégré dans un IDE.
Il peut être utilisé pour d’autres scénarios d’intégration dans vos applications lourdes.
De nombreux clients intègrent ce protocole, permettant d’intégrer différentes solutions Agentic, en évitant les intégrations n x m. Cela permet de stabiliser l'écosystème, foisonnant d’idées nouvelles.
Complétion
Initialement, l’IA est entrée dans les IDE via la fonctionnalité de complétion. L’utilisateur décrit dans un commentaire le rôle d’une nouvelle fonctionnalité, le LLM propose une implémentation qu’il suffit de valider.
Comment cela fonctionne ? Un LLM est là pour produire un texte à la suite d’un autre. Il n’est pas fait pour modifier le milieu d’un fichier. Pour résoudre ce problème, les requêtes vers les API de complétion de codes sont formaté de la manière suivante:
- Tag spécifique
- Fragment de code avant l’insertion
- Tag spécifique
- Fragment de code après l'insertion
- Tag de complétion
Le LLM spécialisé a appris sur ce schéma et va proposer une implémentation. C’est l’intégration dans l’environnement de développement qui va présenter la proposition à la position du curseur. Le protocole ACP aide à l’intégration.
Pour conclure
Un agent de coding n’est pas très éloigné d’un agent classique. Certaines solutions, comme Goose, considèrent la combinaison des outils d’aide au développement comme une extension optionnelle d’une boucle agentique.
Il faut voir ces agents comme des solutions génériques, devant pouvoir être remplacées du jour au lendemain par une autre alternative, si les licences sont plus économiques, les résultats meilleurs, etc. Copilote propose une API. D'autres solutions sont sur le même constat, et proposent des usages hors du codage.
Certaines solutions proposent déjà de nombreux modèles distants ou locaux. Il est trivial de changer de modèle, voir, de laisser la solution choisir le meilleur suivant les besoins (mode auto ou via des API compatibles pour Claude Code par exemple).
Il est important de s’imposer le respect des normes et spécifications sous-jacentes, pour permettre une migration dans quelques mois.
La montée en puissance des Skills va permettre de proposer les meilleures pratiques pour la génération de codes, les audits, la recherche de bugs, etc.
Finalement, ces outils sont parfaitement adaptés à l’implémentation de solutions métier. Gérer un sinistre pour une assurance, rechercher des fraudes pour une banque, rédiger un rapport réglementaire ou améliorer un vertical métier, ces solutions peuvent être mises en œuvre, sans “vendor lock-in”.
Enfin, de nouvelles approches modifient radicalement le développement, avec des IDA “Agent first”, des agents pour rédiger des spécifications complètes, avant génération de code, etc. Nous avons encore de nombreuses évolutions à intégrer, pour faire évoluer notre métier.